
Megsaccolt narancslétől egy Slack-szintű app megírásáig: mire képesek az AI agentek 2025 végén?
Jelenleg 30 órán át tudnak önállóan dolgozni a mesterséges intelligenciát használó ügynökök, ám ez a szám havonta duplázódik, mondta el interjúnkban Lencsés Gergő, az MIT-SMR Hungary vezetője.
„Aki 2025 vége felé még mindig a hallucinációról beszél fontos problémaként, az a kókler kategóriában van” – jelentette ki interjúnkban Lencsés Gergő, az MIT-SMR Hungary vezetője, a ZEL Group Zrt. Senior Partnere. A szakértőt az AI-ágensekről a HR Festen tartott előadása kapcsán kérdeztük. Arról is beszélt, hogy a SaaS halott, az AI-ügynökök használatával tisztább adataink lehetnek, a fejlesztéseket nem ritkán akadályozzák a céges adatvédelmi előírások, a gépektől pedig gyakran többet várunk, mint az emberektől.
Az előadásodban bemutatott AI Agent LinkedIn-kommentet írt. Mondanál még néhány példát a felhasználási területekre, illetve hogy azok miben mások, mint ha csak egy AI workflowt alkalmaztak volna?
A gépi intelligencia fejlődésének három része volt. Az első volt a szabályalapú: ha ez van, akkor ezt csináld. Utána jöttek a neurális hálók, ami alapvetően egy mintázatfelismerés és az arra adott válasz. Ami lehet egy újabb mintázat – a köznyelv ezt hívja AI-nak, jelentsen ez bármit is. Az AI agentek pedig ettől is különböznek, illetve a robotizált folyamatautomatizálástól (robotic process automation, RPA) is. Utóbbi is arról szól, hogy egy automata belép ebbe vagy abba a rendszerbe. Egy agent azonban nagyon, fundamentálisan más. Mégpedig két dologban. Egyrészt felismeri a környezetét, amiben dolgozik, másrészt ez alapján döntéseket hoz, és magától tanul.
Az ágensi működésre jó példák az AI-rendszerek, például a Google-féle Gemini deep research funkciói. Arra keresik ugyanis a megoldást, hogy azzal, amit a felhasználó beírt, mit akar ténylegesen kérdezni. Ezt lebontja feladatokra, a Gemini például meg is mutatja ennek a lépéseit, amin lehet is módosítani. Ezt követően kezd el dolgozni, – nagyon leegyszerűsítve – meghív erőforrásokat, például internetes keresést, és folyamatosan reflektál az eredményekre. Már ez is egyfajta agentic működés. Emellett adattisztításra vagy adatkiegészítésre elképesztően jó. Megtörtént eset, hogy egy cégnél a cikktörzsben nem volt meg minden adat, néhány hiányos volt. Ez viszont egy egész folyamatot használhatatlanná tesz. Konkrétan nem tudtak kiszállítani egy megrendelést, mert a szállítmányozási laphoz be kellett írni azt, hogy hány kiló a termék. És volt tíz doboz literes Hohes C narancslé, amihez a cikktörzsükbe nem volt beírva, hogy hány kiló.
Képzések ebben a témában:
AI a gyakorlatban: ChatGPT, Gemini és más eszközök
András Schenkerik
Founder & CEO, Emprove

AI-ágensfejlesztés az alapoktól
István Sajtos
Vice President, Head of AI Division, PeakX

Bár ez egy embernek végtelenül egyszerű – egy picivel lehet nehezebb, mint egy kiló –, egy szabályalapú rendszer képtelen megoldani, ha hiányzik egy ilyen információ. Egy agent azonban ezt is meg tudja oldani. Ez esetben a felhasznált AI-ügynök háromféle megoldást talált. Az egyik magát a terméket vizsgálta, tudta a hetedikes fizikát, amely alapján egy liter víz az körülbelül egy kiló, így a csomagolással együtt 1 kg és 20 gramm lett az első válasz. A második metódus az volt, hogy az interneten keresett egy literes Hohes C tömeget. Valamiért talált egy 1,2 kilogrammot. A harmadik irány mentén pedig a saját adatbázisában talált Hohes C almalétömeget, és feltételezte, hogy a kettő nem lehet annyira különböző. Majd összevetette a három választ, azt látta, hogy a neten talált 1,2 kiló kilóg, így arra jutott, hogy 1,02 kilogramm a narancslé tömege. Ez elsőre nem nagy truváj, de gondoljunk bele, hogyha ezt 40 ezerszer kell megcsinálni!
Ebben az esetben mi volt a prompt?
Annyi, hogy ha duplikált adatokat találsz, azt töröld ki, ha pedig hiányosakat, azt egészítsd ki. Illetve hogy ehhez megvannak az erőforrásaid: kereshetsz az interneten vagy a belső adatbázisban, és matematikai számításokat is el tudsz végezni.
Az így kipótolt adatok mennyire megbízhatók? Azért kérdezem, mert hagyományosan a hallucináció szokott felmerülni az AI egyik gyakori problémájaként.
A legjobbak már nagyon jól el tudják nyomni azt, amit hallucinációnak hívunk. Ami egyébként azért van – ezt sokan nem értik –, mert a hiányos kontextust próbálja a gép kitölteni válasszal. Vagyis ha nem adsz neki hiányos kontextust, akkor egyre inkább megoldható a hallucináció problémája. Részleteiben nem belemenve abba, hogy a context window milyen hosszú, a gép mindig válaszolni akar neked. Ha adsz neki teret a hülyeségre, akkor abban az esetben is fog, amikor nem kellene. Ehhez kicsit több kell, mint pusztán jó promptolás, de mi például már 2023 közepén tökéletesen el tudtuk nyomni a hallucinációkat. Épp ez az egyik titka a sikerünknek, ugyanis aki ezt a kihívást jól megoldja, az könnyebben tud agenteket lépni.

Lencsés Gergő a 2025-ös HR Festen (forrás: HR Fest)
Tehát mondhatjuk, hogy a hallucináció a jobbaknak már nem probléma. Aki 2025 vége felé még mindig a hallucinációról beszél fontos problémaként, az a kókler kategóriában van. Nagyon sokat kell rajta dolgozni, de mostanra ez már egy meghaladható probléma. Minket már alapvetően azért fizetnek, mert folyamatosan jól el tudjuk nyomni azt, amit hallucinációnak neveznek. A kérdés másik fele, hogy ne gondoljuk, hogy a nem AI-generálta adatok olyan tiszták és jók lennének! Jellemző kettősség, hogy sokkal magasabb az elvárásunk a gépek felé, mint az emberek irányába. Rengetegszer hallucinálunk mi, emberek is, kiegészítjük a meglévő információkat a saját gondolatainkkal és spekulálunk. Csak ezt nem hívjuk hallucinációnak, hanem azt mondjuk, hogy dumálgattunk valamiről, amit nem tudunk pontosan.
Magyarul a hallucináció megfelelő kezelésével az AI által gondozott adatok lehetnek akár pontosabbak is?
Tisztábbak inkább. A duplikációkat, triplikációkat meg lehet szüntetni, a hiányos adatokat pedig kicsit spekulatívan ki tudjuk egészíteni, ahogyan a narancslé esetében is történt. Ez a folyamat még az internet előtt indult el. Fordulópont volt, amikor sokan elkezdtek SQL-adatbázisok helyett nem strukturált adatbázisokat, más néven data lake-eket használni. Ekkor ugyanis az történt, hogy mindenki behányt mindent ezekbe, így ugyanolyan használhatatlanok vagy még rosszabbak voltak, mint előtte az SQL-adatbázisok. Bár szeretjük emlegetni, hogy az adatok milyen jól használhatók, a valóság gyakran nagyon kiábrándító. Sokszor az információk nem elég diverzek és elképesztő kosz van bennük. Megtörtént, hogy egy számlázási rendszerben az IBM Magyarország háromféleképpen szerepelt: végig nagybetűs IBM-mel, majd egy szóközzel a Magyarország előtt, szóközökkel a három betű közt, illetve Hungaryvel a végén. Ezeket egy AI agent lazán tudja már kezelni: kiszúrja a redundanciát, megnézi a cégjegyzékben, hogy a három közül melyik a pontos, és azt hagyja meg.


Az AI agentek hogyan valósulnak meg B2B, B2C vagy kifejezetten egy-egy cég számára fejlesztett konstrukcióban?
Magyarországon ez utóbbiban gondolkodnék. Olyan tempóban fejlődik a terület, hogy háromnegyed éve én is azt mondom, hogy a SaaS (szolgáltatott szoftver) halott. Az informatikai cégeknek abba az irányba kell menniük, hogy B2B modellben maguknak fejlesztenek prototípusokat, és később ezeket adják oda az ügyfeleiknek, hogy ők abból egy használatra kész változatot készítsenek. Az Anthropic új, kutatási előzetesként kiadott „Imagine with Claude” funkciója a Claude Sonnet 4.5 modell képességeit demonstrálta a valós idejű szoftvergenerálás terén. Ez a rendszer alapvetően szoftverprototípusokat csinál, és döbbenet, mire képes. Amikor pedig az említett Sonnet 4.5 30 órás ciklusban autonóm módon programozott, kihozott egy Slack bonyolultságú programot 11 ezer sorral, ami működött. Nem majd ilyen okos lesz, hanem már most az! Az agentic világban a fő mérőszám az, hogy az ágenseid mennyi ideig tudnak önállóan dolgozni. Most ez a 30 óra a plafon, de a szám havonta duplázódik.

Lencsés Gergő a 2025-ös HR Festen (forrás: HR Fest)
Mennyire nehezítik meg a felhasználást az adatvédelmi kérdések? Nem is elsősorban a GDPR-ra gondolok, hanem arra, hogy a cég érzékeny üzleti adatait be merik-e táplálni ilyen rendszerekbe?
Ha nagyon akarják, hogy egy saját szerveren egy AI agent valakinek az asztal alatt kütyürögjön, azt is meg lehet csinálni. Ezek is már egyre olcsóbbak, és jól használható nyílt forráskódú megoldások is elérhetők. Mi is csinálunk ilyet. Egyébként egy AI-ügynök körülbelül ugyanannyi adatvédelmi veszélyt hordoz, mint mondjuk az Outlookod. Ugyanazokon az Azure és AWS szervereken, mint az üzleti levelezés. Szóval én úgy látom, hogy túl van egy kicsit aggódva a kérdés. Az a gond, hogy azok beszélnek róla, akik nem csinálják, akik pedig aktívak a területen, azok gyakran nem tudnak érdekesen beszélni róla.
Nem akadályozzák a céges policyk az ilyen fejlesztéseket?
De igen. Én ezelőtt egy dollármilliárdos üzletrészt vezettem. És az a tapasztalatom, hogy a vállalati jogászok és a kényelmes életüket élő IT-vezetők gyakran inkább nemet mondanak. Pedig – ez az igazán elkeserítő – jellemzően úgy két A4-es oldalt kéne csak elolvasni. Például az említett Anthropic-féle Claude-nak az adatkezelési elvei az első három sorban benne vannak. Ezt oktatással lehet feloldani. Én is ezért igyekszem nagy lendülettel és mosollyal előadni a témáról. Valahol sikerült meggyőzni az illetékeseket, máshol nem, ott másfajta megoldást használtunk. Ami drágább lett nekik, és nem is annyira jó, de legalább az előírásoknak megfelelt.
Ha valaki szoftverfejlesztőként, techvállalkozóként vagy csak a prompt engineert már meghaladni igyekvő felhasználóként AI agentet hozna létre, mennyire magas a belépési küszöb?
Annak, aki valaha írt tíz sornál több kódot, vagy a vizsgálatban jó, iszonyatosan alacsony. Most jött ki az Open AI Agent Buildere. Még tanulom a szintaktikáját, de elsírom magam gyönyörűségemben. Ebben az én agentic Hello World applikációm elolvassa az összes levelemet, és megmondja, mi belőle a prioritás, és mivel mit kellene kezdenem. Mindezt két óra alatt megcsináltam, azt is azért, mert meg kellett értenem, hogy az API-kulcsokat hogyan használja a Microsoft. Ez ennyire egyszerű. Indulás, levélolvasás, és vége. Ha belekattintok, látszik, mi a prompt, és mik hozzá az eszközök. Ennyire fájdalmasan egyszerű. Nyilván most csak annyit csináltam vele, amivel megismerem a szintaktikáját. Ha hozzá akarom adni mondjuk a Gmailt is, az is pár kattintás.
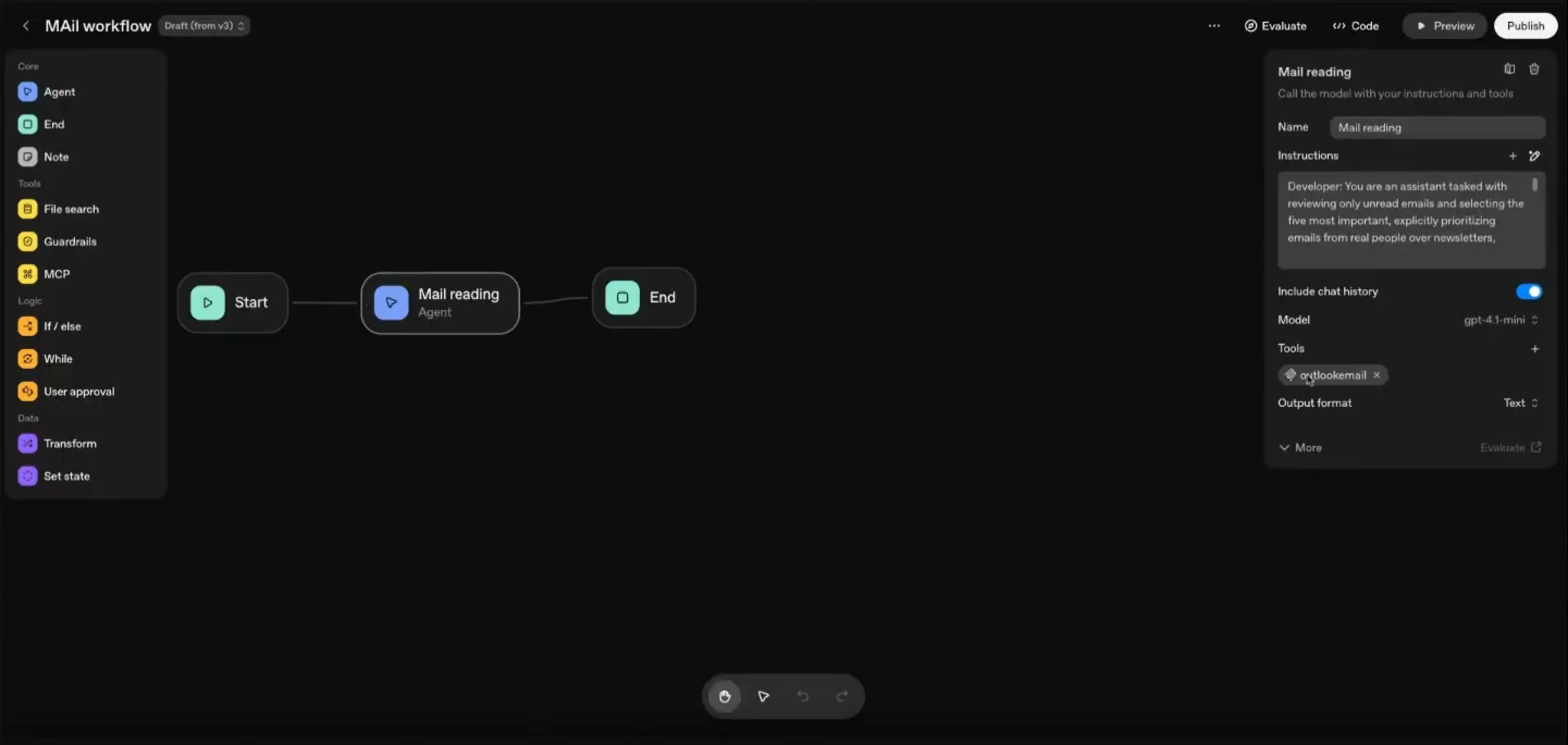
Az említett mail workflow (forrás: Lencsés Gergő)
Arra számítok, hogy a cégek – a teljesen kezdő munkatársakat is beleértve – innentől megcsinálják a maguk prototípusát, az ilyen kis összeragasztott dolgaikat, és odaadják a fejlesztőknek. Ők pedig ezek alapján fogják elkészíteni a készre hegesztett dolgokat, amit akár tízezrek is tudnak majd használni. És ez még a maximális alulgondolása az AI agentek képességeinek. Azokat nemcsak folyamatban kell szervezni, hanem feladatközpontúan, csapatokban.


